


My experience in migrating our production self-managed MongoDB clusters to Atlas.
Introduction:
In this article, I will describe how we migrated our Self managed MongoDB clusters which are hosted on our AWS infrastructure to the managed Atlas service while keeping high availability of services and preventing users to detect any change.
Before proceeding with the Migration, let us get to know about what is MongoDB and Atlas MongoDB.
What is MongoDB?
MongoDB is a popular open-source NoSQL (Not Only SQL) database system that stores data in a flexible, JSON-like document format. It was first developed in 2007 by MongoDB Inc., and since then, it has become one of the most widely used NoSQL databases in the industry. It also features a powerful query language that supports a wide range of operations, including filtering, sorting, aggregation, and geospatial queries. It also provides support for indexing, sharding, and replication, allowing it to scale horizontally across multiple servers.
What is Atlas MongoDB?
Atlas MongoDB is a fully-managed cloud-based database service for MongoDB, a popular document-oriented NoSQL database. Atlas MongoDB is offered by MongoDB Inc. and provides users with an easy way to deploy, manage, and scale MongoDB databases on major cloud platforms like AWS, Google Cloud Platform, and Azure.
One of the advantages of this approach is the “PayAsYouGo” business model, which allows for optimized costs for time-limited workloads.
Why Migrating to DBaaS:
We believe in the values of SaaS, we like to eat our own cake too, switching towards a DB as a Service allows us to have higher flexibility in adding new clusters, resizing existing ones, and reducing management costs. It’s also worth mentioning that MongoDB evolved its strategy and MongoDB Professional has now a lower priority compared to the “as a service” offering.
Atlas allows MongoDB to:
Prevent MongoDB deployments on unsupported architectures;
Reduce configuration errors by customers;
apply optimizations and fixes that might be complex to maintain (when they involve kernel, filesystem, Linux process management, etc)
Reduce compatibility problems: granting proven solutions deeply integrated with the main three Public Cloud vendors.
Migration strategy:
Migrating towards a different infrastructure while keeping our direct management of the DB would have been simpler because we would have had control over configurations, cluster topology, and networking: this would have enabled us the possibility to create a new node on the new infrastructure, synchronize it and then, gradually, remove nodes from the old cluster while adding nodes to the new one.
Unfortunately, this migration strategy is not possible when moving towards an “as a Service” architecture where you are forced to create a new cluster from scratch, migrate data from one cluster to the other, ensure the synchronization is completed, and ultimately migrate the query workload… this also means you have to update all the applications that use the DB.

This means there’s a critical “toggle” moment where you move the production load from the old infrastructure to the new one, this calls for a carefully defined migration process.
We have identified a few key challenges that needed particular attention during the planning and execution:
With a data size of 4.6TB, performing the migration with minimal downtime and the possibility of inconsistent data was a huge risk
Performance concerns with the new database version and cloud-hosted database.
Downstream application and Data pipeline impacts due to the upgrade of the database from the older 3.6.9 version to the newer 4.2.23 version.
We ensured to make the following steps:
Plan a technical assessment with MongoDB architects
Establish peak performance on “old” architecture and test the “new” one against the same load to size it
Accurately define migration plan
Ensure our monitoring and alerting are perfectly working during migration
Accurately define the rollback plan.
Testing the Migration plan with SandBox Environments:
We first created a sandbox environment of the application and integrated Atlas MongoDB into it. Then performed load testing to generate performance metrics for comparison between the old and new versions, and performed manual testing and automated regression testing to ensure that there are no issues in the application functionality. A migration playbook to perform the migration was created which was validated and refined on different sandbox environments.
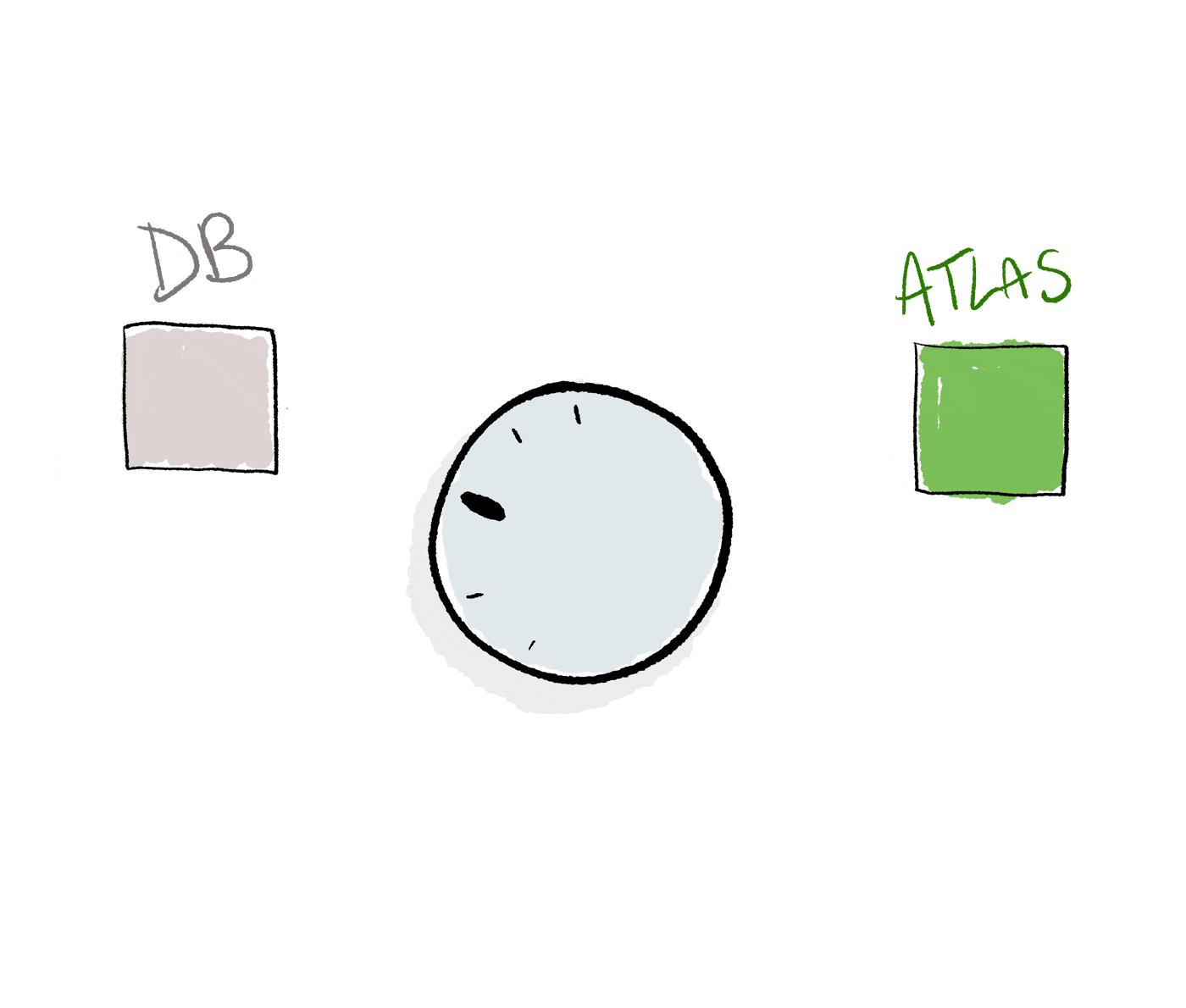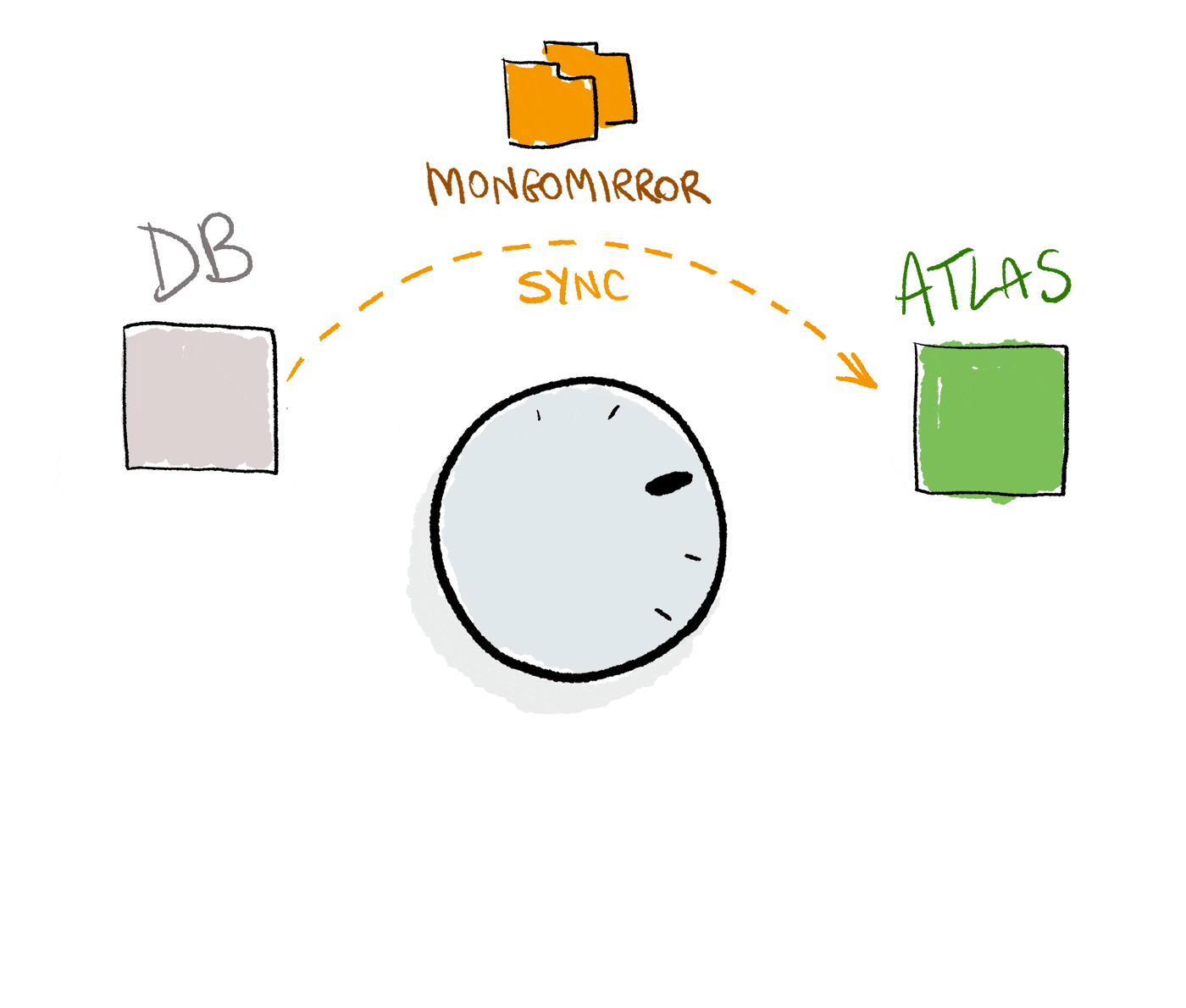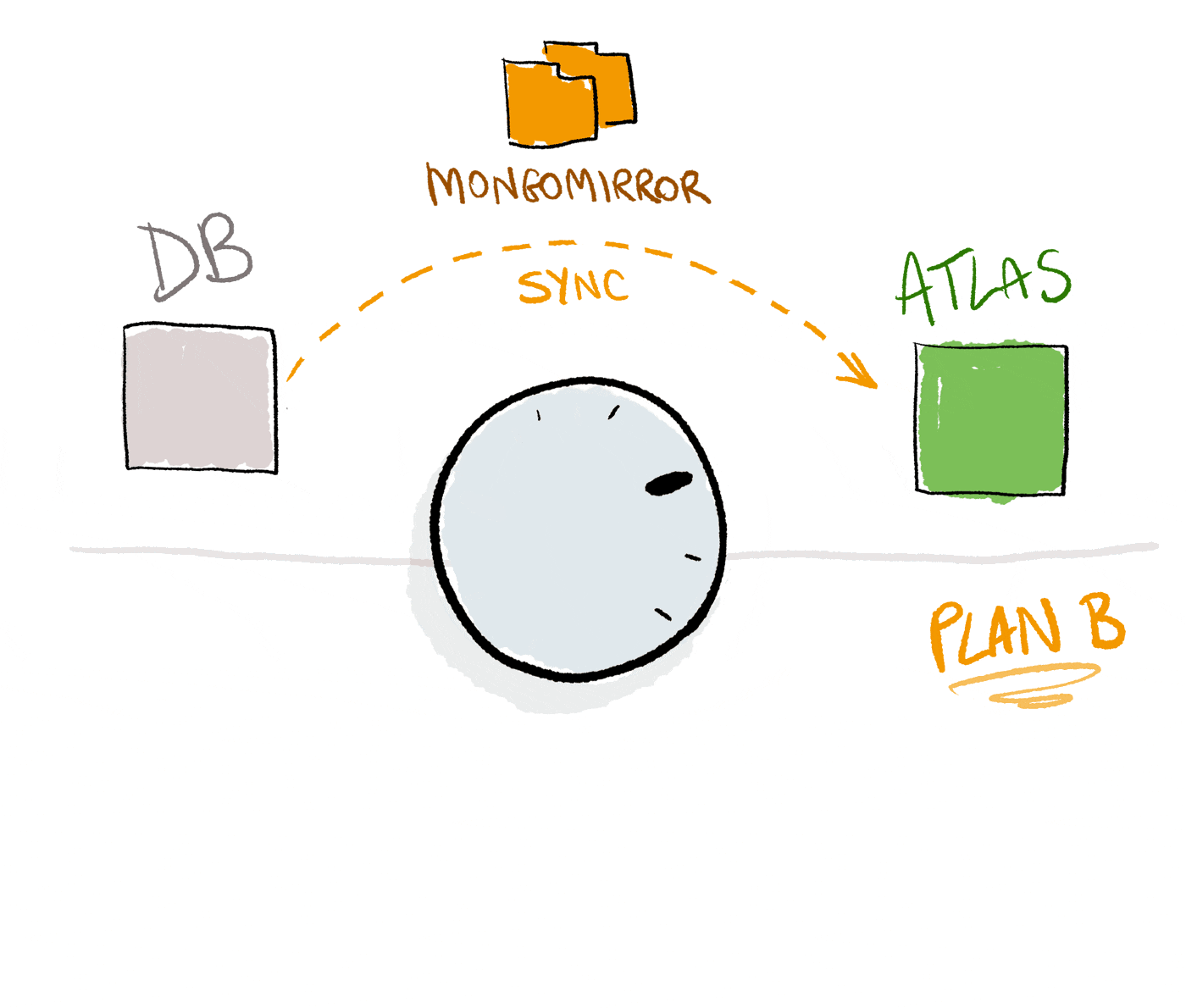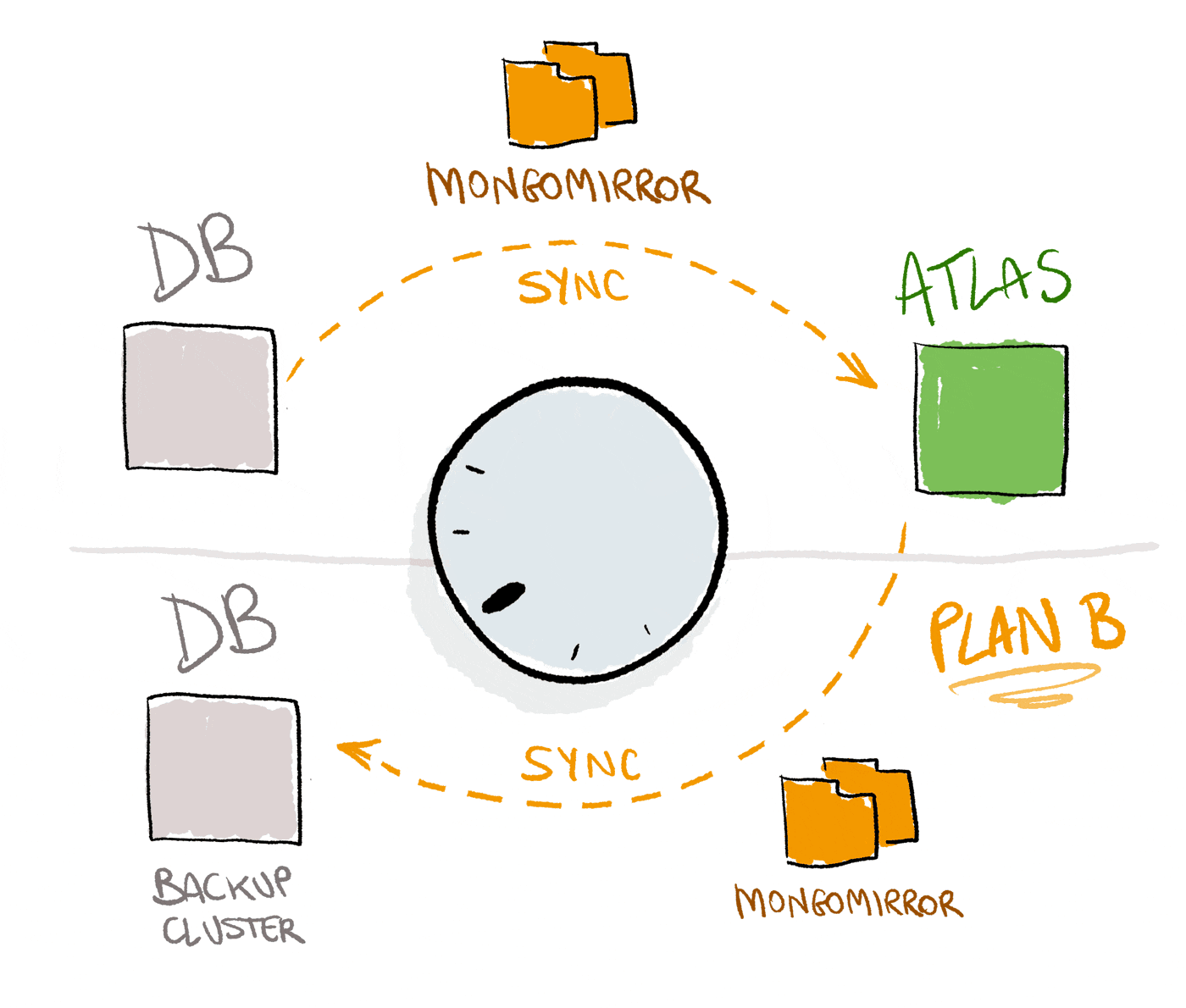
As a rollback option, we set up an additional mirroring process that feeds data from Atlas to a self-hosted backup cluster. The idea of the backup cluster was to exercise the rollback option in case we run into unexpected issues with Atlas.
Data migration:
In order to keep data in sync between the two clusters, we could use either LiveMigration or Mongomirror.
LiveMigration is an agent, managed by Atlas that doesn’t require any installation from the customer and keeps data sync active for up to 72 hours.
We chose to use a more “low level” approach by using MongoMirror (that requires to be installed) which reads Oplogs from the source and replicates them on the destination cluster. Mongomirror has no limitations and can be kept active as long as necessary for the migration.
So as part of the actual production migration, We triggered the MongoMirror process 10 days in advance to monitor the mirroring in depth. The low-risk downstream applications were migrated and tested one by one.
On M-day, during the application downtime, the connections to the self-hosted database were constantly monitored and a cooldown period was allotted for these connections to be terminated.
Conclusion:
This migration was finally completed successfully with minimal disruption to existing services (within an approved 2-hour downtime window over the weekend) with zero post-migration issues reported by anyone. We also continued to monitor for new errors and performance issues for a week after the migration and had a standby plan to roll back the migration in case of any major issues.